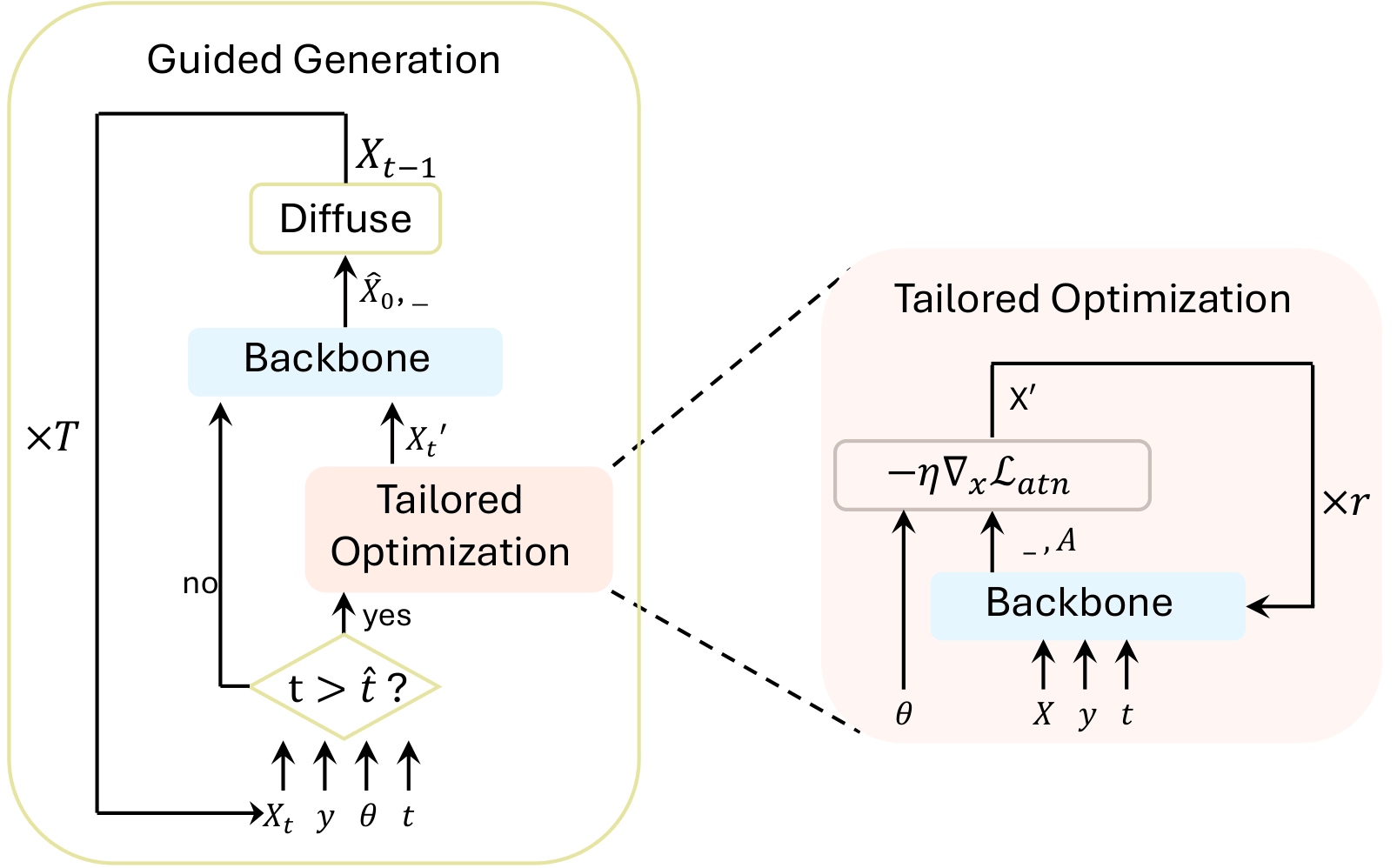
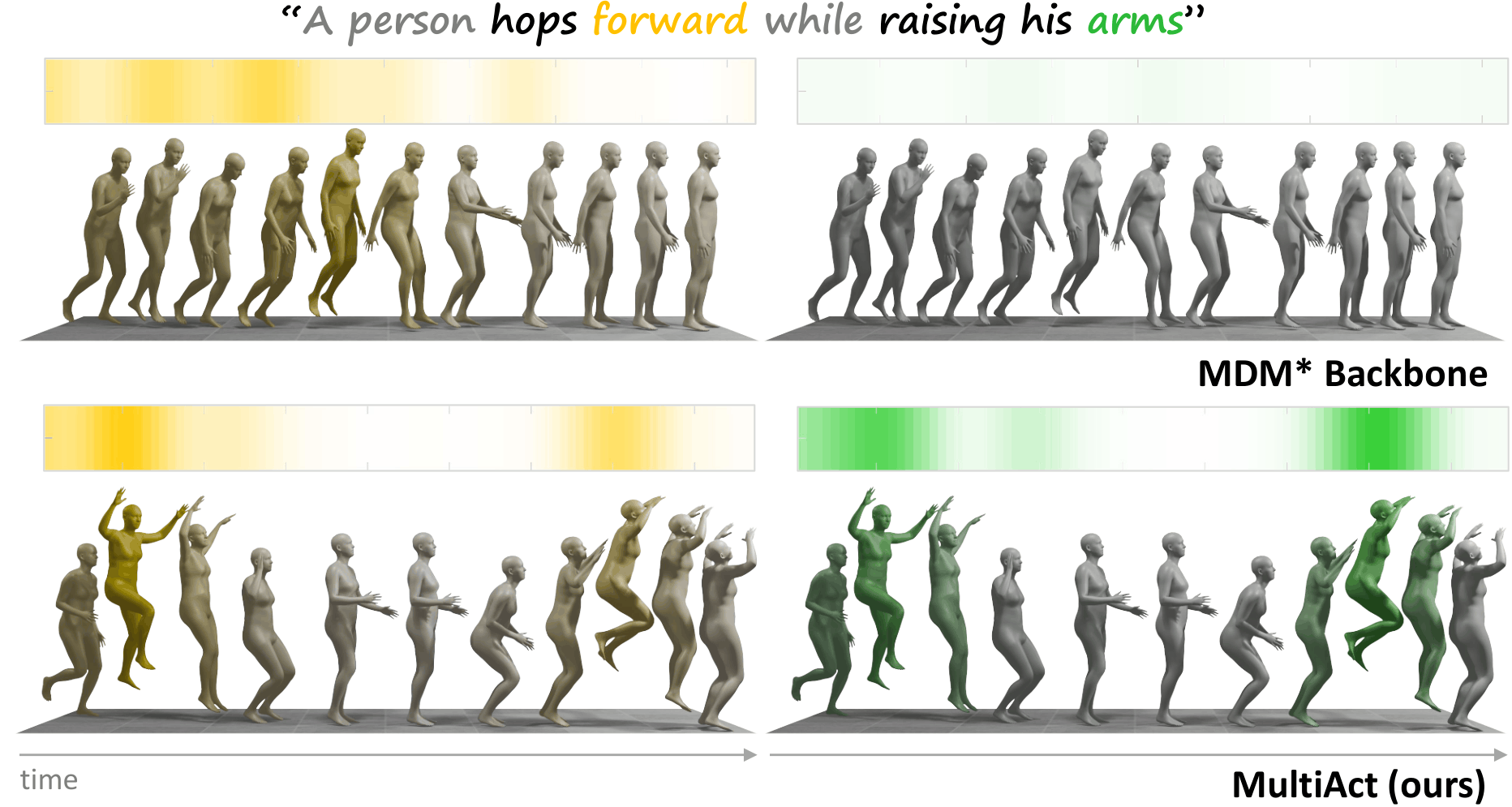
MultiAct is designed for prompts that describe multiple actions or modifiers simultaneously. Instead of allowing a single dominant action to override the rest, it amplifies underrepresented prompt components through attention guidance.
By selectively strengthening cross-attention signals for weakly represented tokens, MultiAct synthesizes motions that capture all specified semantic elements while maintaining motion realism and temporal coherence.
This approach mitigates semantic collapse in composite text prompts and enables more reliable generation across diverse motion descriptions.